ID3 で決定木っぽいクラスタリング?
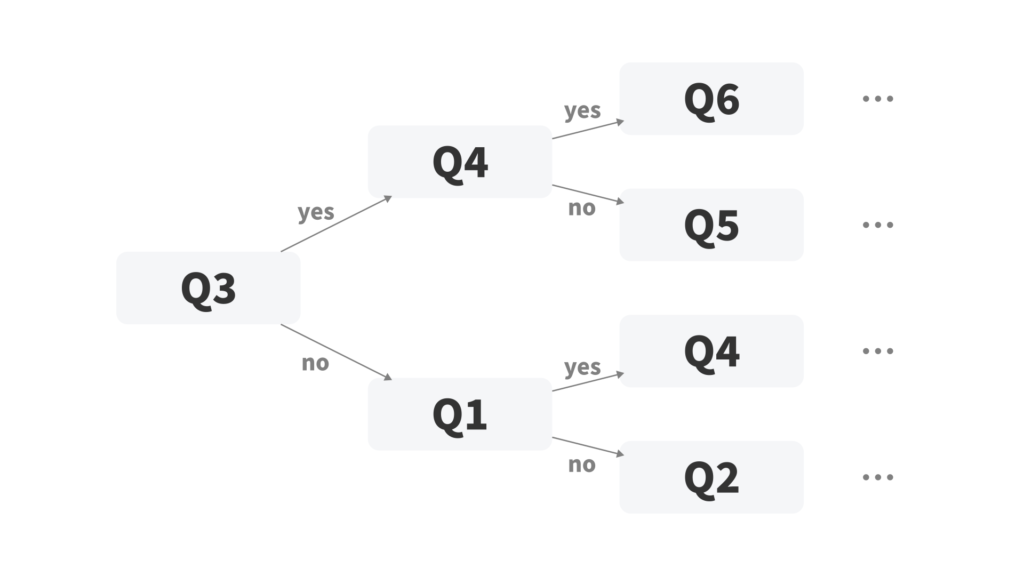
こんなデータがあるとしよう
「はい」か「いいえ」で答えられる調査に 1,000 人が回答した。この回答者を階層的にクラスタリングしたい。データは下の表のような感じ。
| 回答者 ID | 質問 1 | 質問 2 | 質問 3 | 質問 4 | 質問 5 |
|---|---|---|---|---|---|
| 0001 | いいえ | いいえ | はい | いいえ | はい |
| 0002 | いいえ | いいえ | はい | はい | はい |
| … | … | … | … | … | … |
| 1000 | はい | はい | いいえ | いいえ | いいえ |
このとき、平均情報量が最も大きい質問でズバッと分割するのはどうだろう?要するに「できるだけ半々に近い線で切る」ということ。例えば各質問の回答者数が下表のようなら、平均情報量が最も大きい「質問 3」で分割する。
| 回答 | 質問 1 | 質問 2 | 質問 3 | 質問 4 | 質問 5 |
|---|---|---|---|---|---|
| いいえ | 264 | 490 | 506 | 138 | 792 |
| はい | 736 | 510 | 494 | 862 | 208 |
| 平均情報量 [bit] | 0.83272 | 0.99971 | 0.99990 | 0.57898 | 0.73764 |
すると、質問 3 に「はい」と答えた群と、「いいえ」と答えた群に分かれるね。そのそれぞれの群に対して同じように、平均情報量が最大の質問でもう一度分割する。これを繰り返していくと、データを特徴的な集団に分割できないかな?
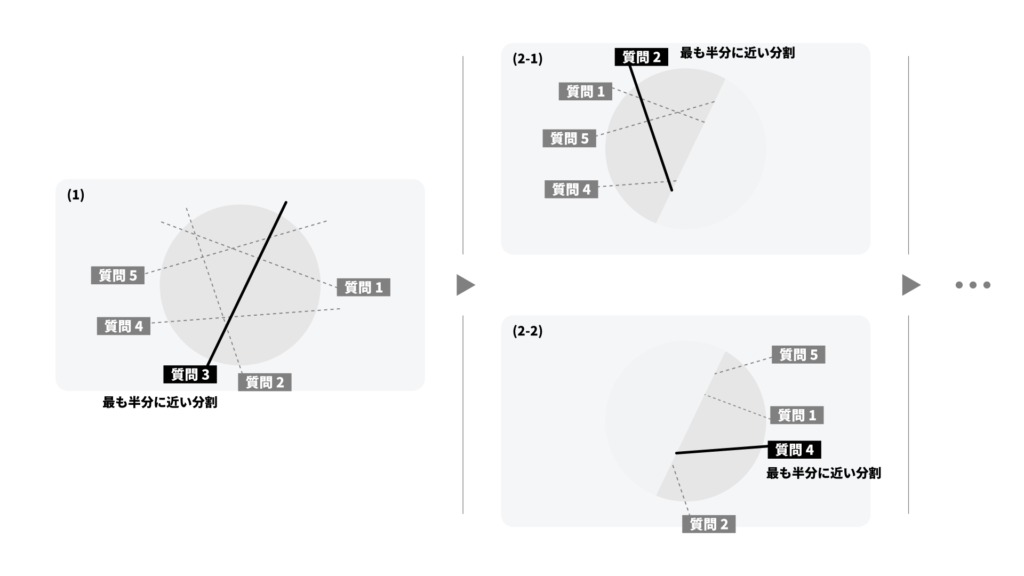
強いて言えば ID3 に似てる?
上記の手法は、特別な状況を仮定した ID3 (Iterative Dichotomiser 3) とおそらく同じ。すなわち、各質問への回答自体を分類 (正解ラベル) としてしまって、ID3 で決定木を作るのと同じだと思う。クラスのエントロピーは分割の前後で、質問の平均情報量の分だけ減る (= 情報利得がある)。
| 回答者 ID | 質問 1 | 質問 2 | 質問 3 | 質問 4 | 質問 5 | 分類 |
|---|---|---|---|---|---|---|
| 0001 | いいえ | いいえ | はい | いいえ | はい | 00101 |
| 0002 | いいえ | いいえ | はい | はい | はい | 00111 |
| … | … | … | … | … | … | … |
| 1000 | はい | はい | いいえ | いいえ | いいえ | 11000 |
今回の分析の目的はクラスタリングであり、回答者をいくつかの群に分けて理解すること。その点で、決定木のような分類問題を解く (予測をする) ための手法は適さない可能性はある。
それでも平均情報量の多い質問で回答者を分割すると、いい感じに回答者をクラスタリングできる気がするのよね。結果の解釈も容易だし。こんな手法にちゃんとした名前があれば、ぜひ教えてください🙏 あるいは学術的にこれが悪い手法だと言える理論があるなら、それを知りたいな。
階層的クラスタリングの手法
確立された階層的なクラスタリングの手法として、Diana 法 (Divisive Analysis) がある。これは上から下の方向に分割していくという点で、上記の方法と通じる点がある。他に下から上の方向 (凝集型) もあるみたいだけど、今回は別の話。
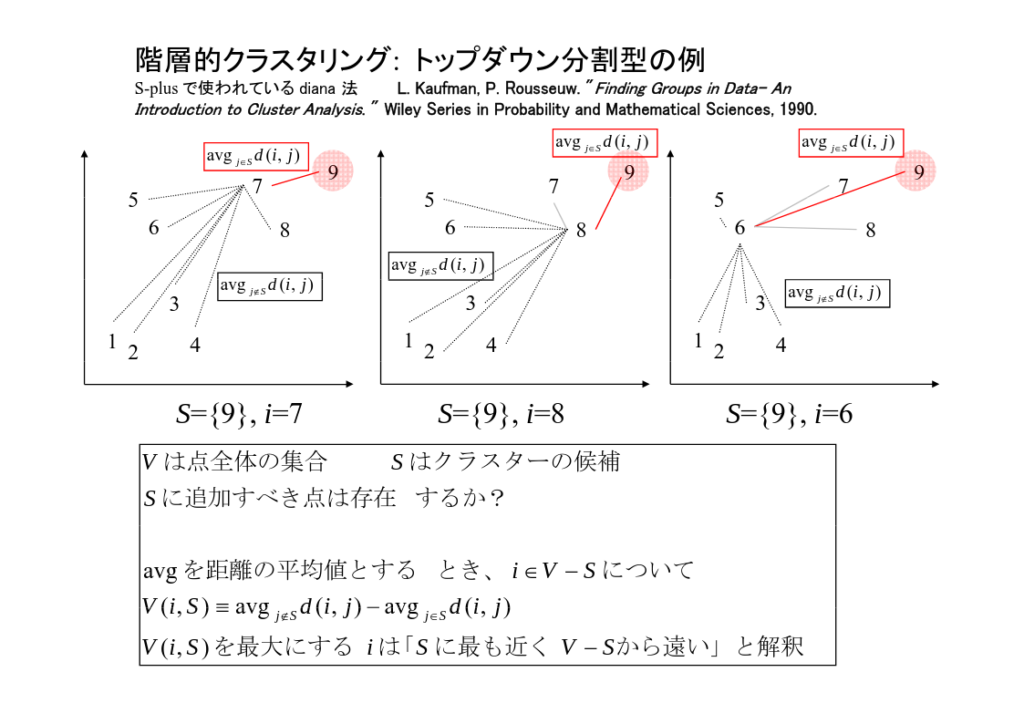
Diana 法を適用できるのは、各データ間に距離が定義できるとき。アンケートの回答のような、距離を定義しにくいデータには適用しにくそう。というわけで僕は、質問の平均情報量で回答者を分割してクラスタリングしてみたくなったのでした。