
駅名から所在地を取得するコマンド

このコマンドでどうでしょうか…?
curl https://ja.wikipedia.org/wiki/高輪台駅 | grep 北緯 | sed -e 's/<[^>]*>//g'
Code language: Bash (bash)コマンドの解説
まず駅名が分かれば https://ja.wikipedia.org/wiki/駅名 とすればそのWikipedia ページに到達できる.ここで言う 駅名 は必ず ○○駅 と,末尾に「駅」と書く必要がある.Wikipediaの「東京」と「東京駅」のページが別だということを考えれば当然だね.上記コマンド (高輪台駅 で実行) の結果はこんな感じ.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 80546 100 80546 0 0 58964 0 0:00:01 0:00:01 --:--:-- 58921
東京都港区白金台二丁目26-7先北緯35度37分54秒 東経139度43分49秒 / 北緯35.63167度 東経139.73028度 / 35.63167; 139.73028駅番号
このコマンドでは curl でページのHTMLリソースを取得して,そこから所在地を取得しているだけ.まず grep で必要な文字列を取得して,そのあと sed でHTMLタグを除去して検索結果をシンプルにしてる.日本は北半球にあるので,駅の所在地情報には「北緯」という文字列が必ず記載されてると思う.
上手く行かない例
僕の把握する限り,2つの失敗パターンがあります.この場合はどうしたらいいでしょうかね… 下を見て解るように,要するに「駅名」を単に書くだけじゃ特定できない場合ってことだね.
- 同名の駅が複数存在する場合
- 同名の駅に複数路線が乗り入れている場合
1については,例えば https://ja.wikipedia.org/wiki/日野駅 がそれに当たる.日野駅と仰る駅は日本全国に3つ (東京都 / 滋賀県 / 奈良県) あるらしく,さらに似た名前の武州日野駅というのが埼玉県にあるらしい.この場合はWikipediaの曖昧さ回避のページが開くので,当然そこには所在地情報はありません.なので curl しても何も取れません.
$ curl https://ja.wikipedia.org/wiki/日野駅 | grep 北緯 | sed -e 's/<[^>]*>//g'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 27252 100 27252 0 0 23842 0 0:00:01 0:00:01 --:--:-- 23842
ちなみにこの場合,駅名に _(東京都) とか付けると回避できる.今回僕は東京都の日野駅について知りたかったので,こんなコマンドで情報を得られる.括弧の前に を付けてエスケープしないと curl がエラーになる (と思う).
$ curl https://ja.wikipedia.org/wiki/日野駅_(東京都) | grep 北緯 sed -e 's/<[^>]*>//g'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 118k 100 118k 0 0 81861 0 0:00:01 0:00:01 --:--:-- 81805
東京都日野市大坂上一丁目9-6北緯35度40分45.29秒東経139度23分38.39秒駅番号
2については,例えば https://ja.wikipedia.org/wiki/新橋駅 がそれに当たる.新橋駅 (東京の駅です) には4路線 (JR / メトロ / 都営地下鉄 / ゆりかもめ) が乗り入れていて,それぞれの駅の場所は当然ながら微妙に異なる.この場合は複数出てくるので,どれが必要なやつなのかを確認する手間があります…
$ curl https://ja.wikipedia.org/wiki/新橋駅 | grep 北緯 | sed -e 's/<[^>]*>//g'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
14 342k 14 49632 0 0 39515 0 0:00:08 0:00:01 0:00:07 39515東京都港区新橋二丁目17北緯35度39分59秒東経139度45分29秒座標: 北緯35度39分59秒 東経139度45分29秒所属事業者
東京都港区新橋二丁目17-5北緯35度40分2.7秒東経139度45分30.5秒駅番号
100 342k 100 342k 0 0 186k 0 0:00:01 0:00:01 --:--:-- 186k
東京都港区新橋二丁目21-1北緯35度39分55秒東経139度45分33.3秒駅番号
東京都港区東新橋一丁目5-13北緯35度39分55.8秒東経139度45分34.7秒駅番号
Wikipedia は構造化されてない?
最初は Google Sheet でスクレイピングすればいいかな?と思ったんだよね.IMPORTXML() を使えば,該当の Wikipeida ページ情報を XPath で取得できる.簡単な使い方の説明はこのQiitaの記事の情報が役に立つと思う.
…が,これでは上手く取得できない.例えば高輪台駅のページの所在地データのXPath はこう.
//*[@id="mw-content-text"]/div/table[1]/tbody/tr[5]/td
しかし別の,例えば三鷹駅の所在地のXPathはこう.ちょっと違う…
//*[@id="mw-content-text"]/div/table[5]/tbody/tr[4]/td
Wikipedia のページごとに記載されてる情報が異なるから,XPath が一定しないんだね (たぶん).そのせいで所在地が取れるときと取れないときがある.ざっとコピペしただけじゃあ上手く行かないんですねぇ.
下の画像は,列Aに 駅名 を書き,列Bに
="https://ja.wikipedia.org/wiki/"&index(A:A, row())&"駅"
列C にこの関数を書き,それを各行にコピーしたもの.index() と row() はいいよね?
=IMPORTXML(index(B:B,row()), "//*[@id='mw-content-text']/div/table[1]/tbody/tr[5]/td")
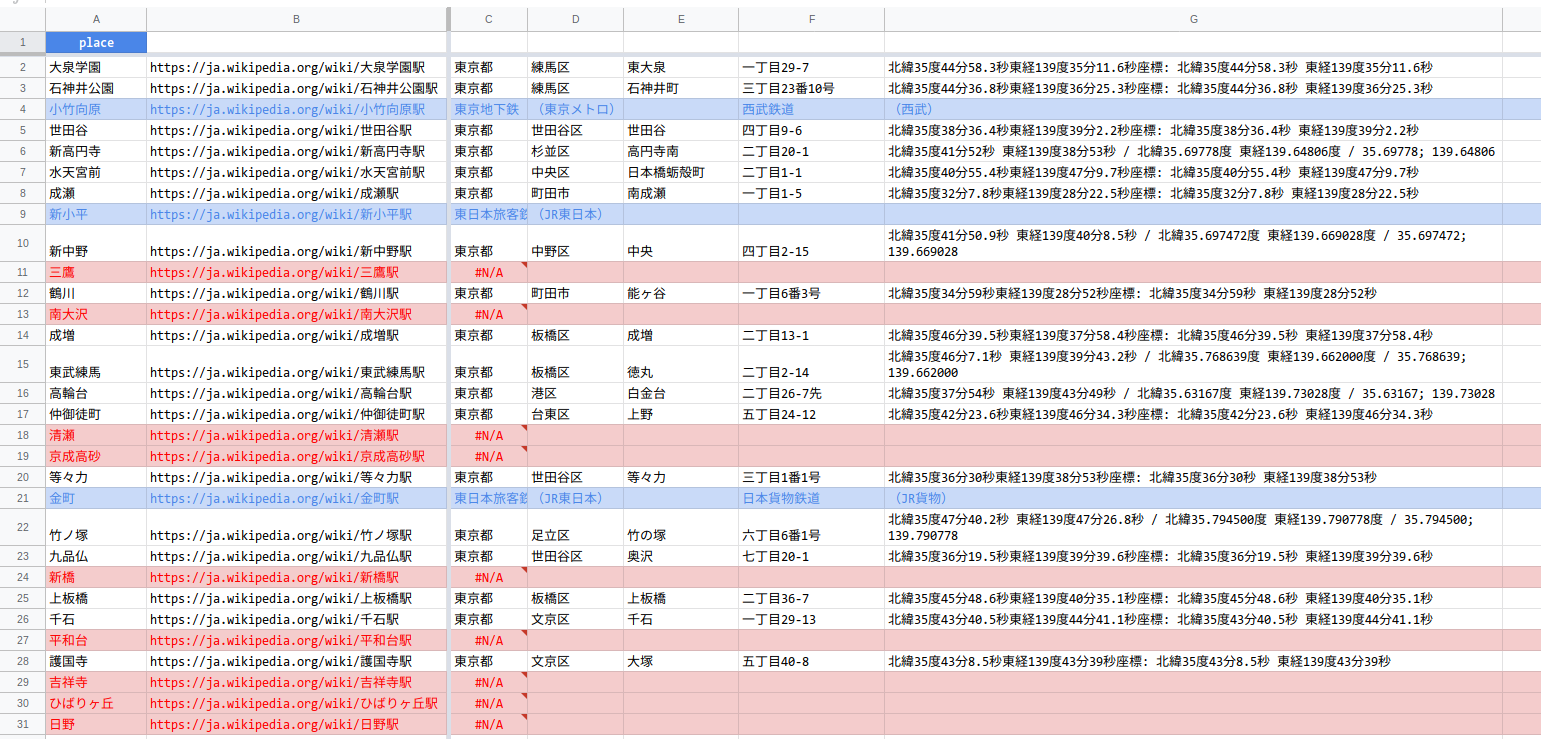
赤い行はデータが N/A .そして青い行は何らかのデータを取れてるけど,それは所在地情報ではないパターン.白いところでは正しく情報が取れてる.まぁ正しく取れてるのはほとんど偶然と言っていいね.なかなか単純には行かないね.ということで,代わりに思い付いたのが冒頭のコマンドなのでした.
ところで
自然言語処理の人とかデータサイエンスの人って,こういうのを wrangle するのが得意なんでしょうか?笑


1件のコメント