
Google Docs で自動句読点
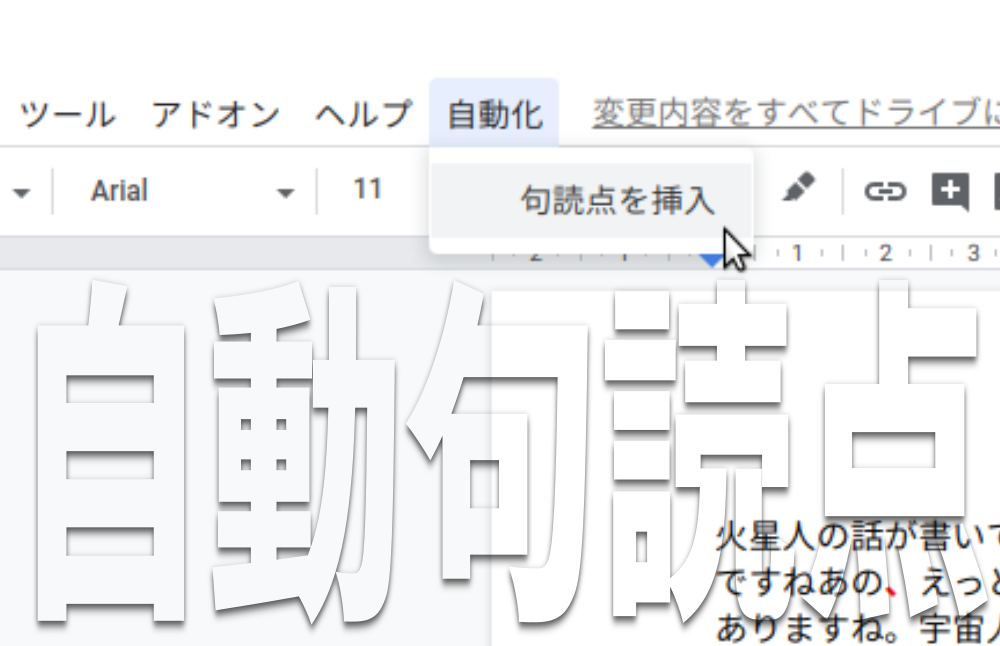
この記事では詳しいことは説明しません!のでサンプルコードを見て感じ取ってね.ちなみに読点の自動挿入には読点「、」挿入システムを使っています.
main.gs
まずはメインの関数.僕は main.gs という名前で使っています.
// UIに実行ボタンを置く
function onOpen() {
var ui = DocumentApp.getUi();
ui.createMenu('自動化')
.addItem('句読点を挿入', 'main')
.addToUi();
}
// 処理の本体
function main() {
//ドキュメントのテキストを読み取る
var doc = DocumentApp.getActiveDocument();
var text = doc.getBody().getText();
//make replece words list1
var arr1 = list1();
text = replace(text, arr1);
// 読点を付ける
text = docPunctuate(text);
// 読点を句点に変える
var arr2 = list2();
text = replace(text, arr2)
doc.getBody().setText(text);
}
Code language: JavaScript (javascript)UI にボタンを置く処理と,本体の処理を合わせて書いてる.本体がすることは:
- Google Docs の本文を取得
- 前処理 (簡単な置換)
- 読点を付ける
- 一部の読点を句点に変える
- 処理結果を Google Docs の本文に書き込む
list.gs
まずは簡単な list1() と list2() を載せましょう.次の内容を list.gs にしてる. list1() は文書を微調整するための置換ペアのリストで, list2() は読点を挿入した後で特定のパターンと読点が並んだ部分を句点 (。) に置き換えるための置換ペアのリストね.読点「、」挿入システムは句点を挿入してくれないので.
function list1(){
var arr = [
['ソフト家', 'ソフトウェア'],
['アップル', ' Apple '],
['ナンバー([0-9]+)', ' No. $1 '],
['ユーチューバー', ' YouTuber '],
['ユーチューブ', ' YouTube '],
/**** 省略 ****/
];
return arr;
}
function list2(){
var arr = [
['こんにちは、', 'こんにちは。'],
['([でま]すと?)、', '$1。'],
['([でま]した)、', '$1。'],
['([ねなよ])、', '$1。'],
['ますで、', 'ます。'],
['([でま]すか)、', '$1。'],
['ください、', 'ください。'],
];
return arr;
}
Code language: JavaScript (javascript)replace.gs
上の list1() と list2() と一緒に使ってる replace() はこんな感じ.これも replace.gs として独立させてる.
// 置換を実行する
function replace(txt, arr) {
//do replace
for(var i in arr){
var re = new RegExp(arr[i][0], 'g');
var txt= txt.replace(re, arr[i][1]);
}
return txt;
}
Code language: JavaScript (javascript)docPunctuate.gs
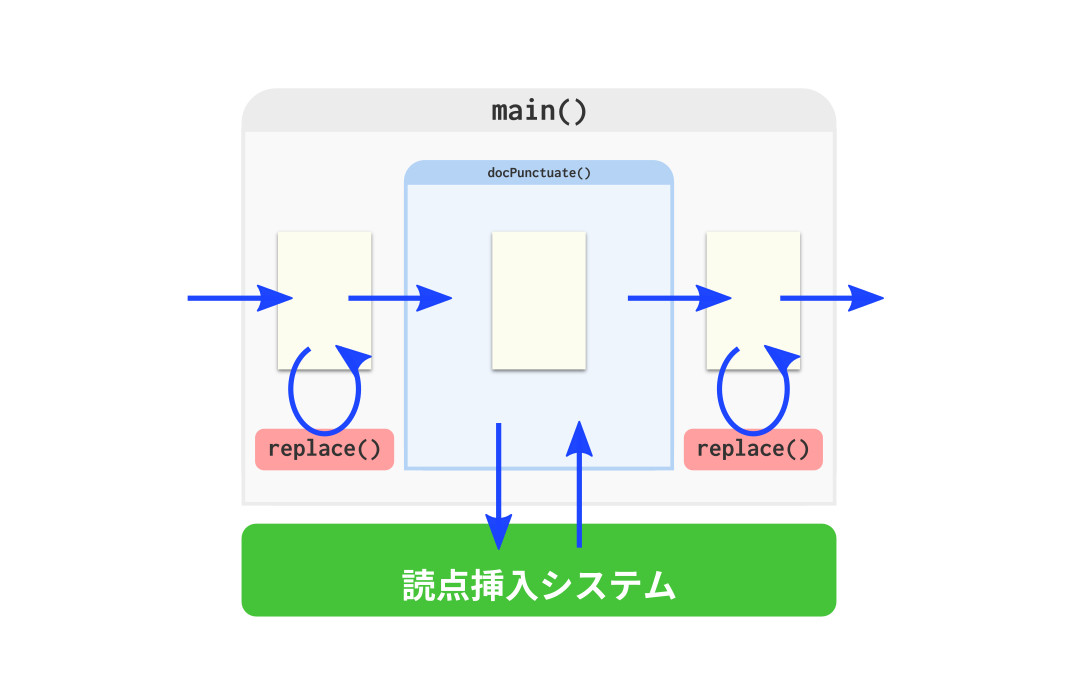
docPunctuate() はちょっと分量が多い.いくつかの処理をまとめて docPunctuate.gs というファイルで使ってます.長いのでそれぞれ掲載するよ.
まず docPunctuate() はこう.分割の単位 size は1000が最適かどうかは分からないけど,あまりにも長いと読点「、」挿入システム側での処理が失敗するので区切ってます.
function docPunctuate(txt){
// テキストを1000文字ごとに分割して読点挿入
var size = 1000;
var len = txt.length;
var out = "";
for(var i=0; size*i<=len; i++){
out += punctuate(txt.substr(size*i, size));
}
return zen2han(out);
}
Code language: JavaScript (javascript)内部で使われている punctuate() はこんな感じ.これについては詳しく書いてるので,その記事もご参照くださいな.
function punctuate(text){
// Endpoint
var url = 'http://pumpkin.i.ryukoku.ac.jp/cgi-bin/dokuten_insert/di.cgi';
// payload を作成
text = EscapeEUCJP(text);
var enter = EscapeEUCJP('予測')
var payload = '';
payload += 'input_sentence=' + text;
payload += '&';
payload += 'enter=' + enter;
// options を作る
var options =
{
"method" : "post",
'payload' : payload
};
// レスポンスの後半だけ残して,タグを取り除いて,1-2行目を消す
var res = UrlFetchApp.fetch(url, options).getContentText('EUC-JP');
res = res.split('<h3>')[2];
res = res.replace(/<("[^"]*"|'[^']*'|[^'">])*>/g,'');
res = res.replace(/^変換文nn/,'');
res = res.replace(/n/gm,'');
return res;
}
Code language: JavaScript (javascript)これで済めばいいんだけど,なぜか読点「、」挿入システムは英数字を全角文字にする驚きの仕様がある (文字コードがEUC-JPなのも驚きだけど…) .全角を半角に戻すために, docPunctuate() は最後に zen2han() という処理を噛ませてますね.ハイフンとチルダは当面は気にする必要がなさそうなので僕はコメントアウトしてますね.
// https://b.0218.jp/20151023001654.html
// ここからコピー
function zen2han(val) {
var regex = /[A-Za-z0-9!"#$%&'()*+,-./:;<=>?@[\]^_`{|}]/g;
// 入力値の全角を半角の文字に置換
value = val
.replace(regex, function(s) {
return String.fromCharCode(s.charCodeAt(0) - 0xfee0);
})
//.replace(/[‐-―]/g, "-") // ハイフンなど
//.replace(/[~〜]/g, "~") // チルダ
.replace(/ /g, " "); // スペース
return value;
}
Code language: JavaScript (javascript)ecl.js.gs
punctuate() でさり気なく使ってる EscapeEUCJP() という関数は GAS の標準ではない.ecl.js というライブラリを使ってますが,210行もあるのでここには書きませんね.




1件のコメント